
前回に引き続き Pycaret の多クラス分類 サンプルコードの後半部分を解説します。少々細かいですが、こちらもデータサイエンティストにとって、強力な武器になる内容が盛り込まれているので、ぜひ参考になさってください。
特にEDAなどの可視化が簡単にできてしまい、恐ろしいくらいです。。。
- はじめに
- サンプルコード解説(Detailed function-by-function overview機能ごとの詳細な説明)
- Set up
- 正規化
- モデル比較
- Experimental logging いろいろ試した結果のログを残す機能
- Create Mode モデル関係
- Tune model モデルのチューニング
- Ensemble Model アンサンブルモデルで学習
- Blend Models
- Stack models
- Plot Model(モデルの描画)
- Interpret Model(特徴量の重要度)
- Get Leaderboard
- AutoML
- Dashboard
- Deep Check
- EDA(探索的データ解析)
- Create app
- Create API
- Create Docker
- Finalize Model
- Convert Model
- Deploy Model
- Save/Load model
はじめに
こちらが、オリジナルの公式ページです。↓↓↓ colaboが実行できて便利ですよ!
そして、こちらが前半部を解説したページです↓↓↓

サンプルコード解説(Detailed function-by-function overview機能ごとの詳細な説明)
今回解説する後半部分は、機能ごとの詳細な説明です。
Set up
s = setup(data, target = 'species', session_id = 123)データセット、ターゲット予測対象(”species”)を選んで、setupしてオブジェクトを作成します。
session_idは乱数のシード固定です。
各パラメータの設定は下記です。(解説いれるかなやみますね)
Description Value
0 Session id 123
1 Target species
2 Target type Multiclass
3 Target mapping Iris-setosa: 0, Iris-versicolor: 1, Iris-virginica: 2
4 Original data shape (150, 5)
5 Transformed data shape (150, 5)
6 Transformed train set shape (105, 5)
7 Transformed test set shape (45, 5)
8 Numeric features 4
9 Preprocess True
10 Imputation type simple
11 Numeric imputation mean
12 Categorical imputation mode
13 Fold Generator StratifiedKFold
14 Fold Number 10
15 CPU Jobs -1
16 Use GPU False
17 Log Experiment False
18 Experiment Name clf-default-name
19 USI 35bc# check all available config
get_config()config 設定を確認します。下記が出力です。
{'USI',
'X',
'X_test',
'X_test_transformed',
'X_train',
'X_train_transformed',
'X_transformed',
'_available_plots',
'_ml_usecase',
'data',
'dataset',
'dataset_transformed',
'exp_id',
'exp_name_log',
'fix_imbalance',
'fold_generator',
'fold_groups_param',
'fold_shuffle_param',
'gpu_n_jobs_param',
'gpu_param',
'html_param',
'idx',
'is_multiclass',
'log_plots_param',
'logging_param',
'memory',
'n_jobs_param',
'pipeline',
'seed',
'target_param',
'test',
'test_transformed',
'train',
'train_transformed',
'variable_and_property_keys',
'variables',
'y',
'y_test',
'y_test_transformed',
'y_train',
'y_train_transformed',
'y_transformed'}# lets access X_train_transformed
get_config('X_train_transformed')学習データを確認できます
# another example: let's access seed
print("The current seed is: {}".format(get_config('seed')))
# now lets change it using set_config
set_config('seed', 786)
print("The new seed is: {}".format(get_config('seed')))乱数シード関連です。途中で変更することは、そんなにないですかね。。。
- 2行目:現在のシード確認
- 5行目:シードを変更しています
正規化
# init setup with normalize = True
s = setup(data, target = 'species', session_id = 123,
normalize = True, normalize_method = 'minmax')正規化です。前処理ですね。
setupの引数で、normalizeをTrue、normalize_methodを”minmax”にしてみています。
特徴量の最小値を0、最大値を1にする正規化です。
# lets check the X_train_transformed to see effect of params passed
get_config('X_train_transformed')['sepal_length'].hist()ヒストグラムをプロットして確認します。
- 2行目:”x_train_transformed”で学習データの説明変数の、”sepeal_length”のヒストグラムプロットします。
.hist()でプロットできてしまいます。便利ですね。。。
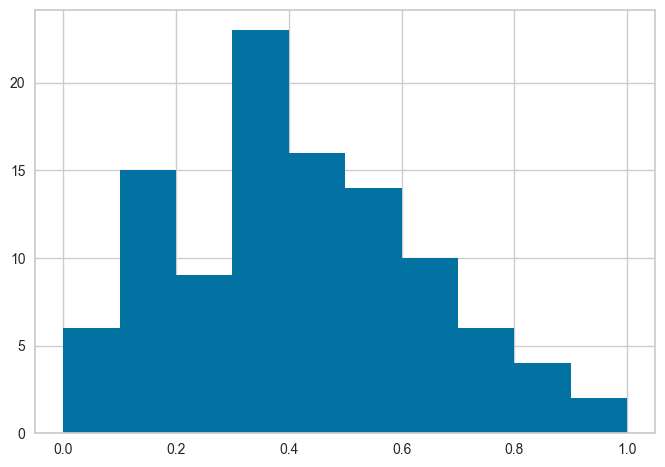
get_config('X_train')['sepal_length'].hist()正規化前のデータのヒストグラムをプロットすると、全然大きい数の間に分布してますよ。
“X_train”で処理前のデータ指定です。
モデル比較
best = compare_models()
Model Accuracy AUC Recall Prec. F1 Kappa MCC TT (Sec)
qda Quadratic Discriminant Analysis 0.9718 0.9974 0.9718 0.9780 0.9712 0.9573 0.9609 0.0380
lda Linear Discriminant Analysis 0.9718 1.0000 0.9718 0.9780 0.9712 0.9573 0.9609 0.0440
knn K Neighbors Classifier 0.9636 0.9844 0.9636 0.9709 0.9631 0.9450 0.9494 0.0510
lightgbm Light Gradient Boosting Machine 0.9536 0.9857 0.9536 0.9634 0.9528 0.9298 0.9356 0.0500
nb Naive Bayes 0.9445 0.9868 0.9445 0.9525 0.9438 0.9161 0.9207 0.0380
et Extra Trees Classifier 0.9445 0.9935 0.9445 0.9586 0.9426 0.9161 0.9246 0.1240
catboost CatBoost Classifier 0.9445 0.9922 0.9445 0.9586 0.9426 0.9161 0.9246 0.0390
xgboost Extreme Gradient Boosting 0.9355 0.9868 0.9355 0.9440 0.9343 0.9023 0.9077 0.0480
dt Decision Tree Classifier 0.9264 0.9429 0.9264 0.9502 0.9201 0.8886 0.9040 0.0340
rf Random Forest Classifier 0.9264 0.9903 0.9264 0.9343 0.9232 0.8886 0.8956 0.1210
gbc Gradient Boosting Classifier 0.9264 0.9688 0.9264 0.9343 0.9232 0.8886 0.8956 0.1500
ada Ada Boost Classifier 0.9155 0.9843 0.9155 0.9401 0.9097 0.8720 0.8873 0.0690
lr Logistic Regression 0.9073 0.9751 0.9073 0.9159 0.9064 0.8597 0.8645 0.0400
ridge Ridge Classifier 0.8318 0.0000 0.8318 0.8545 0.8281 0.7459 0.7595 0.0370
svm SVM - Linear Kernel 0.8100 0.0000 0.8100 0.7831 0.7702 0.7125 0.7527 0.0350
dummy Dummy Classifier 0.2864 0.5000 0.2864 0.0822 0.1277 0.0000 0.0000 0.0380各モデルの精度が表示されます。、Accuracy、AUC、Recall、Precition、F1、Kappa、
# check available models
models()利用可能なモデルを確認すると
Name Reference Turbo
ID
lr Logistic Regression sklearn.linear_model._logistic.LogisticRegression True
knn K Neighbors Classifier sklearn.neighbors._classification.KNeighborsCl... True
nb Naive Bayes sklearn.naive_bayes.GaussianNB True
dt Decision Tree Classifier sklearn.tree._classes.DecisionTreeClassifier True
svm SVM - Linear Kernel sklearn.linear_model._stochastic_gradient.SGDC... True
rbfsvm SVM - Radial Kernel sklearn.svm._classes.SVC False
gpc Gaussian Process Classifier sklearn.gaussian_process._gpc.GaussianProcessC... False
mlp MLP Classifier sklearn.neural_network._multilayer_perceptron.... False
ridge Ridge Classifier sklearn.linear_model._ridge.RidgeClassifier True
rf Random Forest Classifier sklearn.ensemble._forest.RandomForestClassifier True
qda Quadratic Discriminant Analysis sklearn.discriminant_analysis.QuadraticDiscrim... True
ada Ada Boost Classifier sklearn.ensemble._weight_boosting.AdaBoostClas... True
gbc Gradient Boosting Classifier sklearn.ensemble._gb.GradientBoostingClassifier True
lda Linear Discriminant Analysis sklearn.discriminant_analysis.LinearDiscrimina... True
et Extra Trees Classifier sklearn.ensemble._forest.ExtraTreesClassifier True
xgboost Extreme Gradient Boosting xgboost.sklearn.XGBClassifier True
lightgbm Light Gradient Boosting Machine lightgbm.sklearn.LGBMClassifier True
catboost CatBoost Classifier catboost.core.CatBoostClassifier True
dummy Dummy Classifier sklearn.dummy.DummyClassifier Trueよく使うアルゴリズムはほぼ実装されていますね。
SVM、ランダムフォレスト、K近傍、Xgboost、勾配boost、lightgbmもあるので安心です。。。
”あれ試してないの”的な質問されたら、全部やってますよと答えましょう!
compare_tree_models = compare_models(include = ['dt', 'rf', 'et', 'gbc', 'xgboost', 'lightgbm', 'catboost'])モデルを指定してひかくもできます。こちらはツリー系のモデルだけですね。
lightgbmが最高精度みたいですね。。。やはり強いですね。
compare_tree_models_results = pull()
compare_tree_models_resultsこれまでのは、モデルの比較結果を表示するだけするだけです。データとして引っ張り出したときは、pull()を実行します。
best_recall_models_top3 = compare_models(sort = 'Recall', n_select = 3)比較結果の並べ替えもできます。sortで選択します。例では”Recal”で並べて、n_select=3で、top3を取得します。
Experimental logging いろいろ試した結果のログを残す機能
機械学習では、ハイパーパラメータなど様々な値を試しますね。そんな時に、結果を残してくれる便利な機能です。デフォルトでは、
from pycaret.classification import *
s = setup(data, target = 'Class variable', log_experiment='mlflow', experiment_name='iris_experiment')
# compare models
best = compare_models()
start mlflow server on localhost:5000
!mlflow ui- 1~6行目:モデルを設定して、学習しています
- 7行目:mlfllowというログ用のUIを設定して
- 8行目:UIを立ち上げます。
Create Mode モデル関係
# check all the available models
models()利用可能なモデルを確認します。リストが表示されますよ。
# train logistic regression with default fold=10
lr = create_model('lr')ロジスティック回帰をデフォルトのfold 10で実行
# train logistic regression with fold=3
lr = create_model('lr', fold=3)ロジスティック回帰をfold 3で実施
# train logistic regression with specific model parameters
create_model('lr', C = 0.5, l1_ratio = 0.15)ロジスティック回帰の、ハイパーパラメータC、l1_ratio(L1正則化)を設定して学習
# train lr and return train score as well alongwith CV
create_model('lr', return_train_score=True)return_train_scoreをTrueにしておくと、クロスバリデーションで検討した結果を全部の回分表示してくれます。これは、たまに見たくなるところですね。。。モデルの安定感を確認したいときには便利です。
Tune model モデルのチューニング
グリッドサーチなどで、ハイパーパラメータをチューニングする方法です。
# train a dt model with default params
dt = create_model('dt')
# tune hyperparameters of dt
tuned_dt = tune_model(dt)- 2行目:モデルをセッティングして
- 4行目:ハイパーパラメータをチューニング
# define tuning grid
dt_grid = {'max_depth' : [None, 2, 4, 6, 8, 10, 12]}
# tune model with custom grid and metric = F1
tuned_dt = tune_model(dt, custom_grid = dt_grid, optimize = 'F1')- 2行目:グリッドサーチの設定、決定木の”max_depth”を6パターン試します
- 4行目:グリッドサーチ実行します。F1scoreで判断します。
# to access the tuner object you can set return_tuner = True
tuned_dt, tuner = tune_model(dt, return_tuner=True)
# model object
tuned_dt
# tuner object
tunertunerオブジェクトにアクセスしたいときは
- 2行目:引数return_tunerをTrueにしておきます
- 4行目:tunerを見てみます
- 6行目:tunerオブジェクトをダイアグラム(フロー図のようなもの)で見ることができます。
Ensemble Model アンサンブルモデルで学習
# ensemble with bagging
ensemble_model(dt, method = 'Bagging')決定木を、バギングでアンサンブルしています。1行で作ることができて便利ですね。。。
Blend Models
# top 3 models based on recall
best_recall_models_top3
# blend top 3 models
blend_models(best_recall_models_top3)これはBlendモデルです
- 2行目:上の方で計算したtop3のモデルです
- 5行目:3つのモデルをブレンドします。3つのモデルの多数決です。
ブレンドは、基本的に精度が良くなることが多いです。精度を上げるための力技として有効です。
Stack models
# stack models
stack_models(best_recall_models_top3)こちらは、スタックモデルです。スタックモデルは、3つのモデル(今回の例では)の出力を入力値とすして統合するmetaモデルというものを追加して合計4モデルで構成されるものになります。
これも、精度向上は期待できます
Plot Model(モデルの描画)
# plot class report
plot_model(best, plot = 'class_report')各クラスの精度を描画します
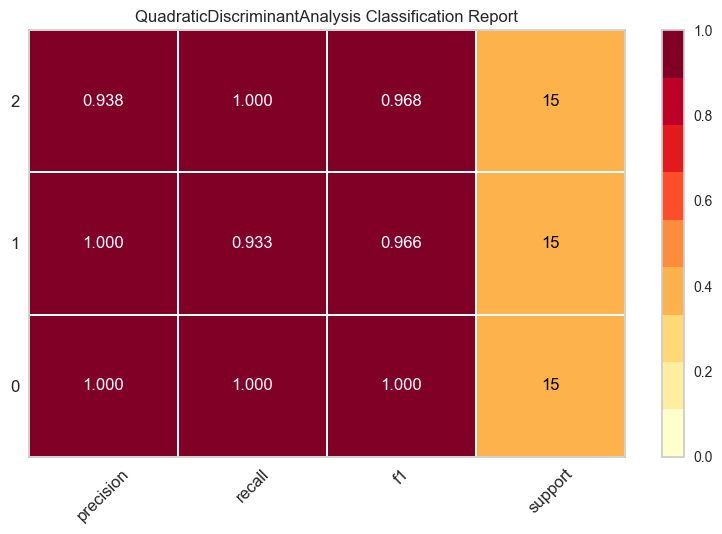
横軸が精度の種類、縦軸がクラスです。3クラス分類ですね。
# to save the plot
plot_model(best, plot = 'class_report', save=True)引数saveをTrueにすると、グラフを保存してくれます。便利ですね。
Interpret Model(特徴量の重要度)
# train lightgbm model
lightgbm = create_model('lightgbm')
# interpret summary model
interpret_model(lightgbm, plot = 'summary')特徴量の重要度のplotです。これは、よく使うので覚えておきましょう。特徴量選択の時で便利ですよ。
- 2行目:LightGBMを学習しておいて
- 4行目:重要度のサマリを表示します
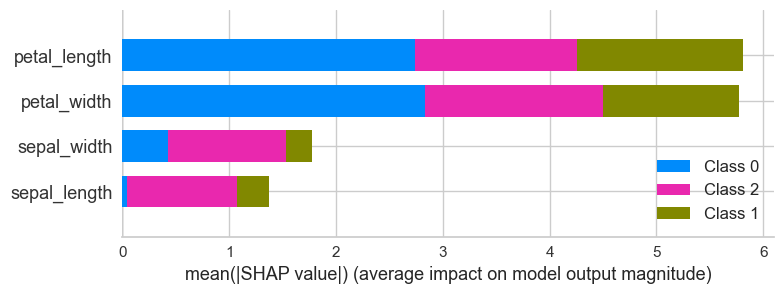
4つの特徴量の重要度です。クラスごとに分析される。SHAP valueという値です。
# reason plot for test set observation 1
interpret_model(lightgbm, plot = 'reason', observation = 1)こちらも寄与度です。
Get Leaderboard
# get leaderboard
lb = get_leaderboard()
lb今の設定で試したすべてのモデルの結果を表示します
AutoML
automl()Auto ML 自動機械学習ですね。今の設定で試した中で一番いいモデルを持ってきます。パラメータ調整も今の設定で行った中でのベスト解です。
Dashboard
# dashboard function
dashboard(dt, display_format ='inline')ダッシュボードをインラインで表示します。colaboやnotebookの時の設定ですね。
Deep Check
# deep check function
deep_check(best)設定等の自動チェック機能です。
EDA(探索的データ解析)
データを眺めてみる機能ですね
# eda function
eda()様々なデータ可視化結果(グラフ)が表示されます。
一通り表示されるので便利ですよ!
Create app
# create gradio app
create_app(best)学習済みモデルで簡単にwebアプリを作成できます。
そのまま、テスト運用できそうです。。。
Create API
# create api
create_api(best, api_name = 'my_first_api')学習済みモデルのAPIを作成します。具体的には、pythonのファイルが出来上がります。
my_first_api.pyというファイルです。これを読み込むと学習済みモデルが使えます。
Create Docker
create_docker('my_first_api')dockerも作成できます。至れり尽くせりですね。。。
Finalize Model
final_best = finalize_model(best)最終的にホールドアウトで学習検証したモデルを保存します。
クロスバリデーションで学習・検証したデータはまとまっていませんからね。
Convert Model
# transpiles learned function to java
print(convert_model(dt, language = 'java'))何と自動で、別言語に変換できます。例ではjavaですね。ほかに、 C, Java, Go, C#, などです。
もはや、有償ソフトより便利な気もします。。。
Deploy Model
# deploy model on aws s3
deploy_model(best, model_name = 'my_first_platform_on_aws',
platform = 'aws', authentication = {'bucket' : 'pycaret-test'})
# load model from aws s3
loaded_from_aws = load_model(model_name = 'my_first_platform_on_aws', platform = 'aws',
authentication = {'bucket' : 'pycaret-test'})
loaded_from_awsAWS,Azure,Gcpなどの形式にdeployできます。上の例はAWSですね。
Save/Load model
# save model
save_model(best, 'my_first_model')
# load model
loaded_from_disk = load_model('my_first_model')
loaded_from_disk最後にモデルのsaveとloadですね。
- 2行目:”my_first_model”という名前でほぞん
- 5行目:モデルをロード
まとめ
今回は、Pycaret Classificationの多クラス分類 サンプルコードの後半部分を解説しました。だいぶ長くなりましたが、どれも素晴らしい機能です。
ぜひ身に着けてみてください。
↓↓↓前半はこちらです

