データサイエンティストに興味があってこれから、学び始めようと思っている方は多いかと思います。
いったいどれくらいのことを勉強すればいいのかわからないですよね。
日本データサイエンティスト協会が、スキルチェック表を作成しており、詳細なスキルを確認できます。
こちらのスキルチェック表は、網羅的に記述されたすばらしいチェックリストです。でも、初心者の方が見てしまうと、多すぎて見るだけで嫌になってしまうと思います。。。
そんな方向けに、初心者の方に特に学んでほしいスキルを、私なりに初めての方でもわかりやすい表現で説明します。
データ分析能力はますます重要になってきております
実際の説明に入る前に、データ分析の重要性の説明をさせてください。
最近は、webやSNS上でのデータ収集や、IOT技術の進化にともなり、センサデータの収集がしやすくなってきています。集まった大量のデータから付加価値を生み出すアルゴリズムを組み立てるのがデータサイエンティストの仕事であり、その重要度は年々増しています。
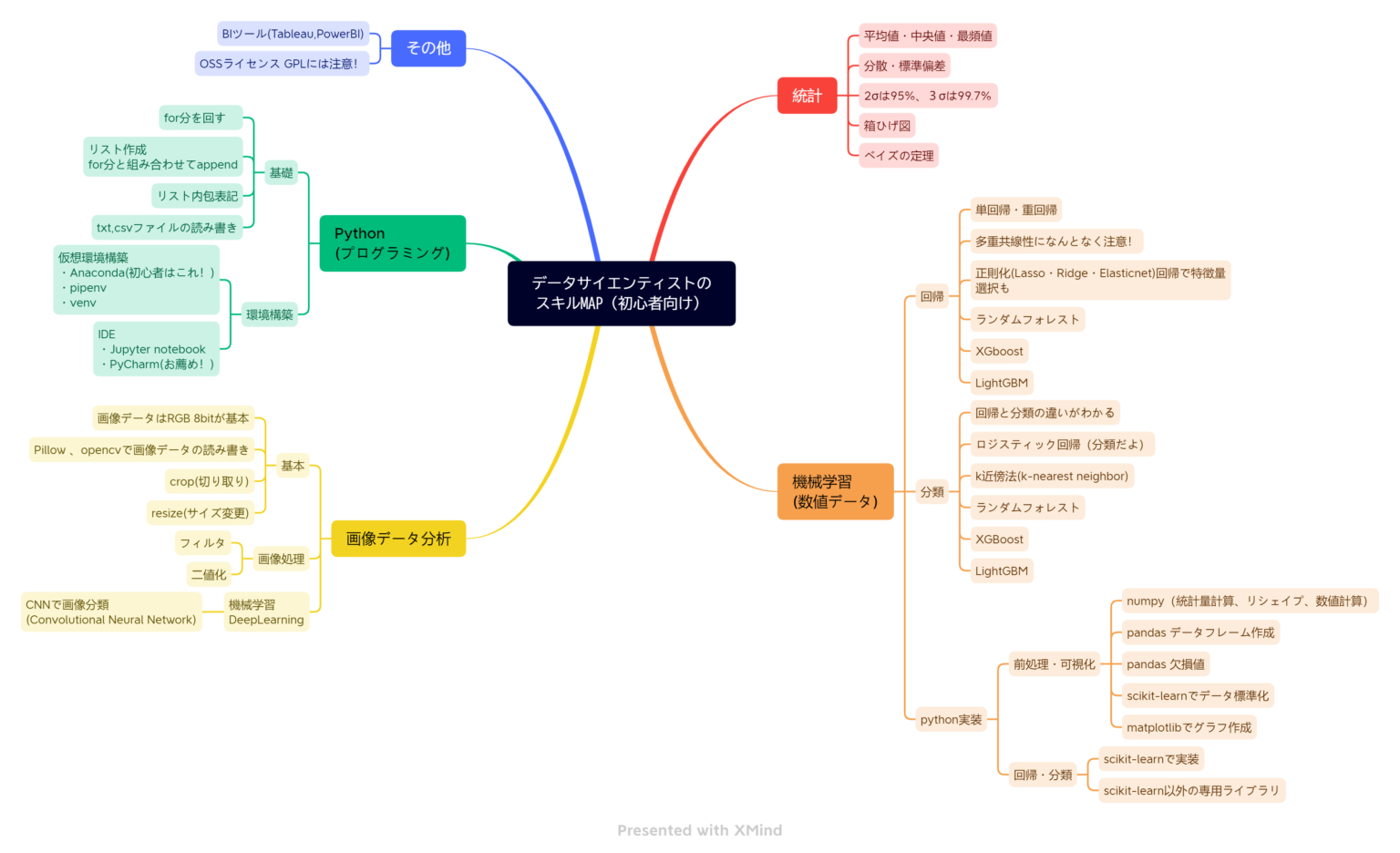
データサイエンティストに必要なスキル35項目
ビジュアル的にわかりやすいようにマインドマップにしています。参考になさってください。
初心者の方は、このMAPを少しづつ埋めていけばいいです。モチベーションも維持できます。
統計
統計学はデータ分析の基本です。このあたりの情報は、ブログや書籍でたくさん手に入ります。
基礎的な統計5項目
- 1 – 平均値、中央値、最頻値の計算
- 2 – 分散・標準偏差の計算。データの正規化・標準化
- 3 – 1σ、2σ、3σの確率を知っている(65%、95%、99.7%)
- 4 – ボックスチャート(箱ひげ図)で分布を表現
- 5 – ベイズの定理をなんとなく理解
統計の勉強はあまり時間をかけず基本的なところだけで十分です。(初心者のうちは)
ボックスチャートは少し難しいかもしれませんが、データを比較するときに便利なビジュアル表現ですので、覚えることをおすすめします。これをサラッと使いこなすと、データサイエンティストっぽいです。
ベイズの定理は、少しとっつきにくいですが、すごく重要なので、こんなのもあるな程度でもいいので、覚えておいてください。

機械学習(数値データ)のアルゴリズム理解とPython実装 回帰・分類

統計の次は、機械学習です。それぞれのアルゴリズムの概要だけで構いませんが、可能なら、Pythonのライブラリを使って分析できるようになりましょう。
回帰5項目
- 6-単回帰・重回帰分析ができる。
- 7-多重共線性がなんとなく理解できて、回帰分析の時注意できる
- 8-正則化 リッジ、ラッソ、エラスティックネットを使って、オーバーフィッテイングを回避。特徴量選択ができる。
- 9-ランダムフォレストで非線形回帰分析ができる。特徴量の選択もできる。
- 10-XGBoostまたはLightGBMを使って非線形回帰ができる。
回帰は5項目書きましたが、重要なのは、9ランダムフォレストと、10XGBoost、LightGBMです。このあたりが、よく使う処理となりますので、かならず、アルゴリズムの概要は覚えておきましょう。初めは、どれも「ツリーモデルが複数あるやつね」くらいでいいです。
ランダムフォレストやエラスティックネットは特徴量の重要度も返してくれるので、これも結構役立ちます。
ツリーモデルのものは、説明変数の標準化や、カテゴリ変数でもあまり気にせず使えるところも便利です。
分類5項目

- 11-分類と回帰の違いがわかる。(回帰は数値予測、分類はカテゴリ予測)
- 12-ロジスティック回帰分析が分類のためのものだとわかっている。(回帰分析なのに)
- 13-k近傍法(k-nearest neighbor)で分離できる。
- 14-ランダムフォレストで分類ができる。特徴量選択もできる。
- 15-XGBoostまたはLightGBMを使って分類ができる。
分類は、回帰と何が違うかは必ず覚えておきましょう。どちらも予測モデルなのですが、数値を予測するのが回帰、カテゴリを予測するのが分類の違いです。
13-k近傍、14-ランダムフォレスト、15-XGBoost,LightGBMはどれも強力なアルゴリズムです。一度は実装まで練習しておきたいです。
分類でもランダムフォレストは特徴量の重要度を返してくれるので、特徴量選択するときは有効です。
Pythonデータ分析実装8項目

- 16-numpyの基本的な使いこなしができる。(統計量計算、リシェイプ、数値計算)
- 17-pandasの基本的な使いこなし。(データフレームの作成)
- 18-scikit-learnでデータの標準化
- 19-pandasで欠損値処理
- 20-matplotでグラフ作成
- 21-scikit-learnで各種機械学習(回帰・分類)
- 22-scikit-learnでランダムフォレスト
- 23-XgboostまたはLightGBM
データ分析用のライブラリの使いこなしになります。
numpy、pnadasでデータの整理や数値計算
matplotでグラフ作成
scikit-learnなどのライブラリをつかって機械学習ができるようになりましょう。
XGboostとLightGBM以外はほとんど、scikit-learnが対応しています。
XGboostやLighGBMなど比較的新しいアルゴリズムは、専用ライブラリをインストールして使います。
画像データ分析
画像データ分析を5項目(必要な方のみ)

- 24-画像データの構造を理解している。RGB3チャンネル8bitです。
- 25-opnecvやPillowで画像データの読み込み、保存ができる。
- 26-画像の切り取り(crop)、サイズ変更(リサイズ)ができる。
- 27-簡単な画像処理ができる。(二値化、エッジフィルタなど簡単なフィルタなど)
- 28-CNN(Convolutional Neural Network)を使って画像分類ができる。ファインチューニングで。
画像データのエンジニアを目指すなら、CNNをぜひマスターしておきたいです。必須の技術になりつつあります。画像処理の基本的なアルゴリズムは数えきれないほどありますが。。。ある程度にしておいて、ぜひCNNを使いこなせるようになりましょう。
CNNは、公開されている学習済みモデルを、自分が予測させたいデータセットに合わせて再学習(ファインチューニング)できるようになりましょう。
プログラミング(Python)
Pythonの基礎4項目

- 29-for分を回すことができる
- 30-リストが作成できる。for分と組み合わせて、appendする処理ができる。
- 31-リスト内包表記を使いこなせる
- 32-txt、csvファイルの読み・書きができる。
データ分析に関しては、基本的な上記4項目くらいをまず覚えましょう。
余裕がある方は、こちらの2冊の書籍での学習がおすすめです。
詳しくはこちらの記事も参考にしてください。

python環境構築2項目

- 33-anacond、venv、pipenvで仮想環境構築
- 34-好みのIDEを選ぶ。おすすめはPycharm
必要なライブラリをインストールした仮想環境というものを構築する必要があります。そのためのツールとしてanaconda、venv、pipenvがあります。初心者のかたは、anacondaがおすすめです。
プログラムを書いたり、実行したり、デバック(途中で止めてみたり)するソフトも自分が使いやすいものを選ぶといいです。私のおすすめは、Pycharmです、料金のかからないcommunity editionで十分です。
その他
その他に少し気にしておいてほしいこと2項目

- 35-BIツールが使いこなせる(Tableau、PowerBI)
- 36-オープンソースのライセンスについてなんとなく理解できている(GPLには注意)
BIツールも使いこなせるといいですね。(この人やるな~と思われますね)
Pythonを使うとオープンソースを使うことになります。Python、numpy、pandas、などなどすべてオープンソースです。それぞれ、ライセンスが定められております。特にGPLというライセンスの種類は注意が必要だということは覚えておいてください。
まとめ
データサイエンティストは、学べば学ぶほど、実力がついてくるやりがいのある仕事です。
ただ、学ぶべきことが多すぎますので、初心者の方は、今回挙げた36項目の中から、手記な順に学んでみていただけると嬉しいです。
特に順番は気にしなくていいと思います。

