機械学習になれていない方は、アルゴリズムが多すぎて、どれを使っていいか悩んでしまうと思います。
はじめに学ぶべきアルゴリズムとして、私がおすすめすのは、ランダムフォレストです。
最近は、XGboostやLightGBMなどに負けていますが、精度が高く、実装が簡単なため、短時間で結果を出す必要があるときには特におすすめです。
webブラウザーで動作するpythonコードを用意しましたので、pythonが動作する環境が整っていない方も気軽に楽しんでください。
おすすめの理由
ランダムフォレストは、決定木を複数作成して、それぞれの決定木の結果を多数決でまとめて、一つの答えを導き出すあるごりずむです。ツリーモデルをたくさん作ります。
データの質がよければ、とりあえず、ハイパーパラメータは何もいじらずとも、そこそこの結果でてしまいます。
scikit-learnを使うと実装も、数行終わりますので、簡単です。
数値データだけでなく、カテゴリデータにも対応していますし、データのレンジ(振れ幅)をそろえる、正規化や標準化の必要もないため、前処理もいりません。
特に初心者の方は、コードが上手く回らずに嫌になってあきらめてしまう方がいますので、ランダムフォレストはおすすめです。
ブラウザーで動くコードで遊んでみましょう!
下の▶ボタンを押すとコードが実行されます。結果右側に表示されますので確認してみてください。
コード解説
データ準備
scikit-learnライブラリでロード可能な、ボストンの住宅価格のデータセットを使います。
ロードして、13種類の説明変数(犯罪発生率とか部屋の広さです)と、予測対象の、住宅価格のデータを使いやすいように変数に格納します。
学習データと検証データに分ける
sk-learnのtrain_test_splitを使って、説明変数と、目的変数(予測対象)を同時に、学習データとテストデータに分けます。今回は7:3に分けます。
学習
学習は、mode.fitの1行です。ハイパーパラメータは今回は特に指定せず、デフォルトのままです。
変えてみたい人は、上のコードで変えてみてください。
フィットさせて検証
予測も、model.predict 1行で済みます。学習デートテストデータそれぞれにフィッテイングさせて、確認します。
考察
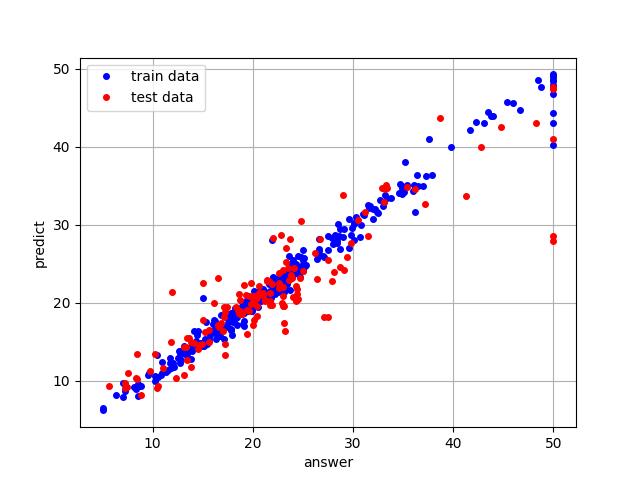
横軸が、実際の住宅の価格、縦軸がモデルによる予測値です。
サンプルの点が、傾き1の直線上にのれば精度が高い状態ですね。
青点は、学習データへのフィッティングの様子で、誤差プラスマイナス10以内に収まっています。学習データへのフィッティングなので、あくまで参考値となります。
赤点がこのモデルの実力となる、テストデータの結果です。実運用での使い方しだいですが、まずまずの結果ではないでしょうか。
まとめ
機械学習のアルゴリズムとして、気軽に楽しめるランダムフォレストを、webブラウザーで動作するコードで説明しました。
ブラウザー上のコードを変更することも可能ですので、初心者の方も機械学習を楽しんでみてください。
