
機械学習のアルゴリズムは、たくさんありすぎて、どれを選んでいいのか迷ってしまいますね。今回は、複数のアルゴリズムを比較したサンプルコードを初心者の方向けに解説します。
はじめに scikit-learn
scikit-learnは、複数の機械学習アルゴリズムが実装されているライブラリです。一つのライブラリで複数のアルゴリズムを比較するときに非常に便利ですね。
今回紹介するのは、scikit-learnのこちらのサンプルプログラムになります。10個の分離アルゴリズムを3種類のデータセットで試して結果を比較しています。
サンプルコード解説
ここから、初心者の方向けにサンプルコードを解説していきます。大事なところは詳しく、高度すぎるところは、なんとなく説明します。
import
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.datasets import make_moons, make_circles, make_classification
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.inspection import DecisionBoundaryDisplay使用するライブラリをインポートしています。
- 1行目 numpy
- 2行目 matplot
- 3行目 matplotの色分け
- 4行目 データを学習データとテストデータに分ける
- 5行目 データの正規化
- 6行目 scikit-learnのパイプライン 処理をつなげてくれるもの
- 7行目 データセット3種類(月型、円型、分類用のデータをつくるやつ)
- 8行目(分類器) ニューラルネットワークのマルチレイヤーパーセプトロン(全結合だけのやつ)
- 9行目(分類器) K近傍法
- 10行目(分類器) SVM(サポートベクターマシン)
- 11行目(分類器) ガウシアンプロセス
- 12行目(分類器) ガウシアンプロセスのRBFカーネル
- 13行目(分類器) 決定木
- 14行目(分類器) アンサンブル学習2種類(ランダムフォレスト、アダブースト)
- 15行目(分類器) ナイーブベイズ
- 16行目(分類器) QDA
- 17行目 分類結果の境界描画
1~6行目は基本的なライブラリ、
7行目は、分析につかうデータセット三種類、
8行目~14行目が本題である、機械学習アルゴリズムになります。
名前と各学習器のリスト作成
names = [
"Nearest Neighbors",
"Linear SVM",
"RBF SVM",
"Gaussian Process",
"Decision Tree",
"Random Forest",
"Neural Net",
"AdaBoost",
"Naive Bayes",
"QDA",
]
classifiers = [
KNeighborsClassifier(3),
SVC(kernel="linear", C=0.025),
SVC(gamma=2, C=1),
GaussianProcessClassifier(1.0 * RBF(1.0)),
DecisionTreeClassifier(max_depth=5),
RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1),
MLPClassifier(alpha=1, max_iter=1000),
AdaBoostClassifier(),
GaussianNB(),
QuadraticDiscriminantAnalysis(),
]
変数namesとして、10個の学習器の名前のリストを作成します。
変数classifiersに10個の学習器にのオブジェクトのリストを作成します。(学習器を10個定義してリストにまとめておきます。)
データセットの作成
X, y = make_classification(
n_features=2, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=1
)
rng = np.random.RandomState(2)
X += 2 * rng.uniform(size=X.shape)
linearly_separable = (X, y)
datasets = [
make_moons(noise=0.3, random_state=0),
make_circles(noise=0.2, factor=0.5, random_state=1),
linearly_separable,
]1~6行目で、ガウス分布に従ったデータセット作成します。特徴量が2個、2クラスのデータセットです。(いろいろ細かく設定していますが、初心者の方は、深追いせずに。)
8~12行目で、さらに、月型のデータセットと、円型のデータセットを作成して、1~6行目で作成したデータセットとともにdatasetsにリストとして格納します。
各学習器の学習と結果表示
学習と結果表示です。2重のfor分で記載されていますので、一気に説明します。少し長いですがご了承ください。
figure = plt.figure(figsize=(27, 9))
i = 1
# iterate over datasets
for ds_cnt, ds in enumerate(datasets):
# preprocess dataset, split into training and test part
X, y = ds
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.4, random_state=42
)
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
# just plot the dataset first
cm = plt.cm.RdBu
cm_bright = ListedColormap(["#FF0000", "#0000FF"])
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
if ds_cnt == 0:
ax.set_title("Input data")
# Plot the training points
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright, edgecolors="k")
# Plot the testing points
ax.scatter(
X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6, edgecolors="k"
)
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.set_xticks(())
ax.set_yticks(())
i += 1
# iterate over classifiers
for name, clf in zip(names, classifiers):
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
clf = make_pipeline(StandardScaler(), clf)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
DecisionBoundaryDisplay.from_estimator(
clf, X, cmap=cm, alpha=0.8, ax=ax, eps=0.5
)
# Plot the training points
ax.scatter(
X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright, edgecolors="k"
)
# Plot the testing points
ax.scatter(
X_test[:, 0],
X_test[:, 1],
c=y_test,
cmap=cm_bright,
edgecolors="k",
alpha=0.6
)
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.set_xticks(())
ax.set_yticks(())
if ds_cnt == 0:
ax.set_title(name, fontsize=10)
ax.text(
x_max - 0.3,
y_min + 0.3,
("%.2f" % score).lstrip("0"),
size=10,
horizontalalignment="right",
)
i += 1
plt.tight_layout()
plt.show()1行目は、matplot作成するグラフの前準備です。
4行目のfor分で、データセットのリストからひとつづつ取り出して回します。
7~9行目で、学習データとテストデータに分けます。
11~12行目で、グラフを書く時の最大値と最小値(レンジ)を決めておきます。
14~19行目で、グラフの設定を行います。16行目でヒートマップに使うカラーマップの設定、17行mでサブプロットの設定をしています。サブプロットは、行方向がデータセットなので3行、列方向は、各学習器の結果にインプットデータを加えるので10+1列となります。18行目のif分で、初めは、タイトルをinputdataにします。
21行目で学習データをプロットして、23~25行目で、テストデータをプロットします。
26~29行目は、グラフのレンジ設定とグラフ間の間隔の設定。
33行目以降は、for 分を回して10個の学習器を試します。
34行目で、結果を各グラフを指定して、
36行目で、データを正規化しています。パイプライン処理を使ってコンパクトに記述しています。
37行目で、学習器を学習します。
38行目で、テストデータに対する精度を計算して、
39~41行目で、決定境界を描画します。
44~46行目で、学習データをプロットして、
48~55行目で、テストデータをプロットします。
57~60行目で、グラフのレンジと、グラフ間の間隔を設定します。
61~62行目で、グラフの各列で、一番上の時だけタイトルを設定します。
63~69行目で、グラフのテキストの設定
最後にfor分二つを抜けて、
72行目でグラフをきつきつのレイアウトにして、
73行目でグラフを表示します。
結果をみてみる
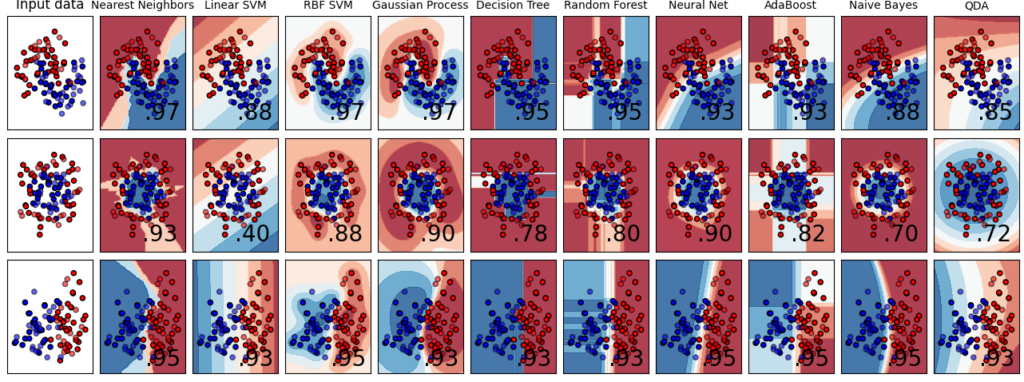
上記プログラムを実行するとこちらの、グラフが表示されます。
どうでしょうか、Decision Tree Random Forestなど、ツリーを用いたモデルは、境界線が直線となりますので、今回のデータに対して使うのはためらってしまいますね。
私が選ぶなら、RBF SVMを選びます、目視でパッと見て引きたい境界線を、曲線で引いてくれています。
昨今、random forestやXGboost、LightGBMなど、ツリーを用いたアンサンブル学習が主流となっていますが、比較的データ数と特徴量が少ないデータには、SVMが強いことがわかります。
様々なアルゴリズムを覚えて、データにあったアルゴリズムを選択できるようになりたいですね。
まとめ
scikit-learnで複数のアルゴリズムを比較する、サンプルコードを紹介しました。データセットを自分の分析対象におきかえれば、簡単に複数のアルゴリズムをためすことができますので、ご活用ください。
データによっては、Random ForestやLightGBM、XGboostなどの手を出したくなるアルゴリズムよりも他のアルゴリズムの方が高精度を出すことも、よくあります。様々なアルゴリズムを使分けたいものです。。。

