
はじめに
Pycaretは、Auto ML(自動機械学習)のオープンソースライブラリとして、最も有名なものです。
Pycaretは、ただ自動で複数のモデルを試してくれるだけでなく、様々なデータ分析の便利機能を備えています。
今回は、便利機能の中でも、最も有益な特徴量の重要度出力機能について紹介します。特徴量選択が必要な場合や理由説明が必要な場合に、とっても嬉しい機能ですので、ぜひ覚えてください。
説明
インストール
# シンプルに入れるなら
pip install pycaret
# フルバージョンなら
pip install pycaret[full]ライブラリのインストールです、コマンドラインで、
- 2行目:シンプルに入れるならこちら。
- 4行目:フルバージョンで入れるならこちら。各ライブラリの依存関係がクリアされているので、こちらがおすすめです。
インポートとバージョン確認
import pycaret
pycaret.__version__- 1行目:pycaretをインポート
- 2行目:バージョン確認
データ準備
# loading sample dataset from pycaret dataset module
from pycaret.datasets import get_data
data = get_data('iris')データを準備します。今回はおなじみの、アイリスデータです。あやめの、ガクや花びらのサイズから種類を予測するデータセットですね。
- 1行目:pycaretのデータ取得をインポート
- 2行目:おなじみのアイリス(あやめの種類分類データセット)を取得
セットアップと学習
データの設定をして、モデルを作成します。pycaretは自動機械学習のライブラリなので、複数モデルまとめて学習かのうですが、特徴量の重要度を可視化するためには、モデルを一つ選ぶことになりますのでご注意ください。
s = setup(data, target = 'species', session_id = 123)
# train lightgbm model
lightgbm = create_model('lightgbm')- 1行目:データセット、ターゲット予測対象(”species”)を選んで、setupしてオブジェクトを作成します。
- 4行目:モデルを作成します。今回の例では、安心のLightGBMにしておきましょう。
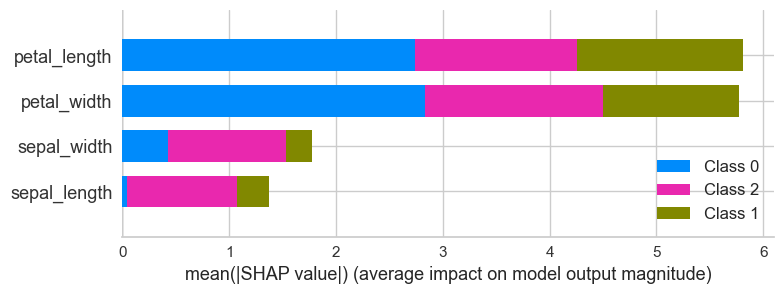
特徴量の重要度
# interpret summary model
interpret_model(lightgbm, plot = 'summary')ここが本題の特徴量の重要度のplotです。よく使うので覚えておきましょう。特徴量選択の時で便利ですよ。
下のグラフのように、4つの特徴量それぞれについて、各クラスへの重要度が可視化できます。
- 2行目:LightGBMを学習しておいて
- 4行目:重要度のサマリを表示します
# reason plot for test set observation 1
interpret_model(lightgbm, plot = 'reason', observation = 1)こちらは、reason plot というものです。簡単に出力されますので試してみてください。
まとめ
自動機械学習ライブラリ、pycaretで特徴量の重要度を出力する方法を紹介しました。
簡単にできて便利ですよね。
これ以外にも、各種グラフ作成など、pycaretは、データサイエンティストが行う分析処理を、簡単に実行できるAPIが用意されていますので、ぜひ覚えてください。

