機械学習アルゴリズムで、精度が出しやすく人気のXGboostのサンプルコードを解説します。初心者向けに日本語で丁寧に補足を加えつつ説明します。
XGboostとは
XGboostとは、LightGBMと並んで、精度が出しやすい機械学習のアルゴリズムです。回帰と分類ができます。複数のツリーを用いる、アンサンブル学習です。
今回説明するサンプルコードはこちらです。

LightGBMについてはこちらで解説しています
サンプルコード解説
今回紹介するサンプルコードのタイトルは、
”Demo for accessing the xgboost eval metrics by using sklearn interface” です。
xgboostのアルゴリズムを、scikit-learnのインターフェースを使って、動かします。また、様々な精度計測方法もためします。
scikit-learnは、xgboost以外にも様々なアルゴリズムが実装されていますので、xgboostを使う方は、なるべく、scikit-learnインターフェースを使うようにしましょう!
ライブラリインポートとデータセット準備
import xgboost as xgb
import numpy as np
from sklearn.datasets import make_hastie_10_2
X, y = make_hastie_10_2(n_samples=2000, random_state=42)1行目で、xgboostをインポート、2行目でnumpyをインポート、3行目で、sikit-learnに実装されている、make_hastie_10_2というデータセットをインポートします。
4行目の、make_hastie_10_2は、正規分布の乱数を使って、10個の説明変数(特徴量)を生成します。また、目的変数(予測対象)はバイナリーデータ(-1か1)として、生成します。2分類のデータセットですね。
引数 n_samplesはデータの個数、random_stateは乱数シードとなります。
したがって、ここでは、Xが2000行10列のデータ、yが2000個のバイナリーデータとなります。
ラベル変換、学習とテストデータ作成
# Map labels from {-1, 1} to {0, 1}
labels, y = np.unique(y, return_inverse=True)
X_train, X_test = X[:1600], X[1600:]
y_train, y_test = y[:1600], y[1600:]
1行目では、-1または、1だった、バイナリデータを、0または1となるように変換しています。必須の作業となります。
2行目で、説明変数Xを学習データとテストデータに分けています。1600:400です。
3行目では同様に、目的変数yを学習データとテストデータに分けています。
学習
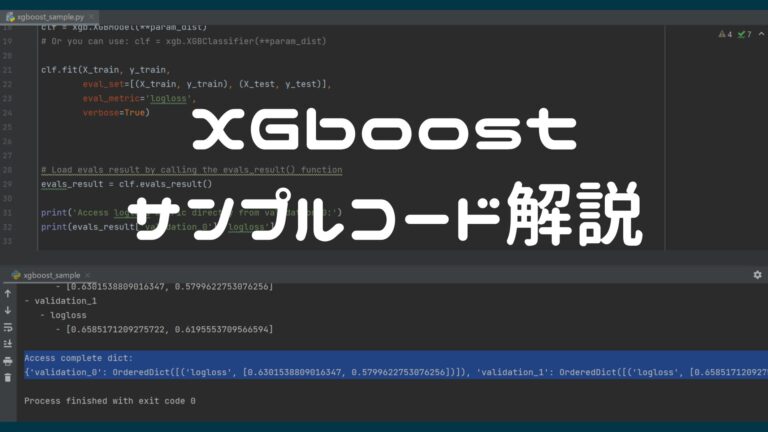
clf = xgb.XGBModel(**param_dist)
# Or you can use: clf = xgb.XGBClassifier(**param_dist)
clf.fit(X_train, y_train,
eval_set=[(X_train, y_train), (X_test, y_test)],
eval_metric='logloss',
verbose=True)1行目で、モデルのオブジェクトを作成し、
2行目で、パラメータをセットして、学習します。
各引数は
- X_train :学習用説明変数
- y_train :学習用目的変数
- eval_set :検証データのセット 学習データとテストデータ両方をつかっている。
- eval_metric :検証時の精度計算方法 loglossを選択
- verbose :学習時の進捗を表示するか
ポイントは、検証データセットに、学習データセットとテストデータセットをタプルのリストで設定しているところです。
精度の表示方法1
# Load evals result by calling the evals_result() function
evals_result = clf.evals_result()
print('Access logloss metric directly from validation_0:')
print(evals_result['validation_0']['logloss'])
print('')1行目で、結果をeval_resultに渡して、2行目以降で表示します。
eval_resultsは辞書形式なので、3行目の書き方で、精度が表示されます。結果は下記のとおりです。
一つ目がクラス0の精度、二つ目が、クラス1の精度です。
Access logloss metric directly from validation_0:
[0.6301538809016347, 0.5799622753076256]精度の表示方法2 for分を使って全部表示
print('')
print('Access metrics through a loop:')
for e_name, e_mtrs in evals_result.items():
print('- {}'.format(e_name))
for e_mtr_name, e_mtr_vals in e_mtrs.items():
print(' - {}'.format(e_mtr_name))
print(' - {}'.format(e_mtr_vals))for分を使ってすべて表記するコードです。
eval_resultは辞書形式なので、2行目で、 items()をつかって、keyと値を返して順番に表示しています。
表示結果は下記のようになります。validation_1がテストデータに対する精度です。
Access metrics through a loop:
- validation_0
- logloss
- [0.6301538809016347, 0.5799622753076256]
- validation_1
- logloss
- [0.6585171209275722, 0.6195553709566594]精度の表示方法3 辞書形式をそのまま表示
print('')
print('Access complete dict:')
print(evals_result)こちらは、そのままプリントしています。evals_resultは辞書形式なので、下記のように表示されます。
Access complete dict:
{'validation_0': OrderedDict([('logloss', [0.6301538809016347, 0.5799622753076256])]), 'validation_1': OrderedDict([('logloss', [0.6585171209275722, 0.6195553709566594])])}まとめ
XGboostのサンプルコードを初心者の方向けに解説しました。XGboostは比較的精度の出しやすい、機械学習モデルですので、ぜひご活用ください。

