LightGBMは、回帰・分類を行う機械学習アルゴリズムで、精度が高いため広くつかわれています。
オフィシャルサイトにサンプルコードがのっておりますが、英語で記述されているのと、少々わかりににくい(コピーアンドペーストで実行できるわけではない。。。)です。
初心者の方向けに、オフィシャルサイトのサンプルコードを動作するように修正を加えて解説します。
LightGBMオフィシャルサイト
LightGBMのオフィシャルサイトはこちらになります。引数やパラメータのセッティングなどは、なるべくオフィシャルサイトを参考にするようにしましょう!
↓↓↓

今回解説するサンプルコードのページはこちらになります。サンプルコードというよりは、APIの説明に近いかもしれませんね。
↓↓↓

サンプルコード解説
インストール Install
ツールのインストールです。pipコマンド1行で済みます。こちらは、コマンドプロンプトでの実行です。簡単ですね。
pip install lightgbmここからが、pythonコードです、初めにインポートも忘れずに。。。ついでにnumpyも入れておきましょう。
import lightgbm as lgb
import numpy as npデータインターフェース Data Interface
ここは、データの入出力の説明です。LightGBMが対応しているデータ形式は下記です。
- LibSVM (zero-based) / TSV / CSV format text file
- NumPy 2D array(s), pandas DataFrame, H2O DataTable’s Frame, SciPy sparse matrix
- LightGBM binary file
- LightGBM
Sequenceobject(s)
使いそうなのは、一番上の、tsv、csvファイル。
上から2番目の、numpの2次元データ、pandasのデータフレームです。迷ったら、pandasデータフレームがいいですね。
numpyデータ読み込み
サンプルコードでは、様々な形式のデータ読み込みが記載されていますが、ここでは使いそうなnumpyだけ説明しておきます。
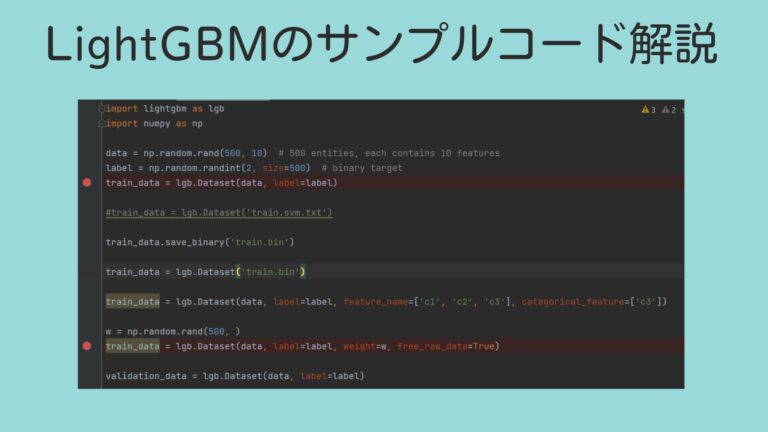
data = np.random.rand(500, 10) # 500 個のデータ, それぞれ 10 個の特徴(説明変数)があります
label = np.random.randint(2, size=500) # 0-1の予測対象。(OK NGみたいなイメージです)
train_data = lgb.Dataset(data, label=label)1行目で、500行10列の乱数を作成しています。
10個の特徴(説明変数)をもつ、500個のデータを模擬的に作成しています。
2行目では、ラベルを作成しています、こちらも乱数で、500個のデータに0か1のラベルを付けています。
3行目で、lightGBM形式のデータセットに変換しています。
バイナリデータで保存
lightGBM形式のデータは、バイナリデータで保存しておいて、次回から、バイナリデータを読み込めば高速に読み込めるそうです。大規模データの時にはやりましょうか。下記は、バイナリで保存する方法です。”train.bin”はファイルのパスです。
train_data.save_binary('train.bin')バイナリデータを読むときは下記です。”train.bin”はファイルのパスです。
train_data = lgb.Dataset('train.bin')バリデーション(検証)データの準備
バリデーションデータも別途用意する必要があります。ここでは、時短のため、train_dataを使ってしまいます。本番の解析時にはまねをしないように。。。
validation_data = lgb.Dataset(data, label=label)データに重みを設定
500個あるデータに、重みを付与することもできます。500個データはあるものの、怪しいデータの重みを小さくしたり、重要と思われるデータの重みを大きくしたりするといいでしょう。
いわゆるドメイン知識のようなものがある場合有効です。
w = np.random.rand(500, )
train_data = lgb.Dataset(data, label=label, weight=w)サンプルコードでは、乱数で重みを設定してしています。乱数で重みを設定するのは、あまり意味がないので、本番ではまねしないように。
メモリ節約方法
メモリ節約方法が3種類紹介されています、大規模データを扱うときには気をつけましょう!
- データセット構築の時に
free_raw_data=True(default isTrue) にする - データセットを構築した後に set
raw_data=None - gc を呼ぶ
とはいえ、一番上の、free_raw_dataは、初期設定でTrueになっていますので、あまり気にしなくていいです。
パラメータ設定
Boosterパラメータを設定します。
param = {'num_leaves': 31, 'objective': 'binary'}
param['metric'] = 'auc'1行目で、各ツリーモデルの、分岐数を31に、目的変数を、バイナリーに設定しています。
2行目で、精度をAUCに設定しています
精度は複数設定することも可能です。リストで設定しましょう。binary_loglossを追加しています。
param['metric'] = ['auc', 'binary_logloss']学習
いよいよ学習です。
num_round = 10
bst = lgb.train(param, train_data, num_round, valid_sets=[validation_data])学習の引数は
- param:設定した学習用のパラメータ
- train_data:学習データ
- num_round:ブースティングのイタレーション回数
- valid_sets:検証データ
本当は、他にもたくさん引数がありますが、初心者の方は上記程度でOKです。
学習済みモデルの保存
学習済みモデルをテキスト形式で保存するならこちら
bst.save_model('model.txt')Json形式で学習済みモデルを保存するならこちら
json_model = bst.dump_model()学習済みモデルのロード
学習済みモデルのロードはこちら
bst = lgb.Booster(model_file='model.txt') # init modelCV クロスバリデーションで学習検証
機械学習でデータ数が少ないときは、交差検証を行います。
lgb.cv(param, train_data, num_round, nfold=5)クロスバリデーションも簡単ですね。引数は下記4項目です。
- param:設定パラメーター
- train_data:学習データ
- num_round:ブースティングのイタレーション回数
- nfold:分割数 迷ったら5
nfoldで分割数を設定します。交差検証なので、バリデーションデータを別に準備することは不要です。
アーリーストッピング
学習を程よいところで打ち切る、アーリーストッピングも可能です。大規模データを扱うときには使わなければならないケースがでてくるかもしれません。
bst = lgb.train(param, train_data, num_round, valid_sets=valid_sets, early_stopping_rounds=5)
bst.save_model('model.txt', num_iteration=bst.best_iteration)1行目の学習で、eary_stopping_roundsで何回目で打ち切るか設定できます。
2行目はモデルの保存です。num_iteration=bst.best_iterationで、一番よかったときの結果を保存します。
推論
推論も簡単です。
data = np.random.rand(7, 10) #7個のデータを乱数でてきとうに準備
ypred = bst.predict(data)1行目で、データ(説明変数)を用意し、2行目で推論を行っています。
もし、アーリーストッピングONで学習したときに、ベストな精度を出したときのモデルを使いたい場合は、下記になります。
ypred = bst.predict(data, num_iteration=bst.best_iteration)num_iterationに、ベスト精度をただき出した、イタレーション数を指定します。
まとめ
初心者の方向けに、LightGBMのサンプルコードを解説しました。
LightGBMは、実用的な精度をだすために、非常に強力なアルゴリズムですので、ぜひ活用ください。
注意点として、シンプルな問題や、データ数が少ない場合は、過学習を起こして使い物にならなくなるアルゴリズム(非線形モデル)です。
シンプルな問題や、データ数が少ない場合は、線形回帰、決定木などシンプルなモデルを使いましょう!

