
pycaretは、前処理や機械学習のモデル選択、ハイパーパラメータ調整を自動で実行してくれる、強力なツールです。pythonで、あーだこーだ書いて試している時間を大きく削減してくれます。
今回は、pycaretのクラス分類問題を解いているサンプルコードを解説します。すべての要素が詰まっている素晴らしいサンプルコードですので、ぜひこちらで勉強してみてください。
少し長いので、前半と後半に分けますが、初心者のかたは前半だけでOKです!
はじめに
今回紹介するサンプルコードはこちらのページの ”Multiclass Classification”です。↓↓↓
ほぼすべての要素が詰まっているのでじっくり進めていきましょう!colaboが用意されているのでそちらが便利です。
回帰分析のサンプルコード解説はこちらをどうぞ↓↓↓
コード解説
インストール
# シンプルに入れるなら
pip install pycaret
# フルバージョンなら
pip install pycaret[full]ライブラリのインストールです、コマンドラインで、
- 2行目:シンプルに入れるならこちら。
- 4行目:フルバージョンで入れるならこちら。各ライブラリの依存関係がクリアされているので、こちらがおすすめです。
インポートとバージョン確認
ここからが、pythonコードです。
import pycaret
pycaret.__version__- 1行目:pycaretをインポート
- 2行目:バージョン確認
データ準備
# loading sample dataset from pycaret dataset module
from pycaret.datasets import get_data
data = get_data('iris')データを準備します
- 1行目:pycaretのデータ取得をインポート
- 2行目:おなじみのアイリス(あやめの種類分類データセット)を取得
Set up (準備)
PycaretのAPIは、(1)Functional(順番に書いていく感じ) と(2) Object Oriented API.(オブジェクト指向で、目的別に機能を引き出していくような書き方)があります。
オブジェクト指向の方がいい気がしますね。わかりやすくて。。。。でも好みで選んでください!
まずは、(1)Functionalのセッテイングです。
# import pycaret classification and init setup
from pycaret.classification import *
s = setup(data, target = 'species', session_id = 123)準備です、1行で終わります。ここでエラーが出る方は、”protobuf”のバージョンを下げる必要があります。エラーメッセージに従って対応してみてください。
- 2行目:pycaretのclassification クラス分類を全部インポート
- 3行目、準備する。用いるデータがdataで、クラス分類の対象が”species” アヤメの種別、session_idは乱数の種です。固定して再現するようにしておきましょう。
(2)Object Oiented APIでの書き方です。 初めにクラス定義しますね。
# import ClassificationExperiment and init the class
from pycaret.classification import ClassificationExperiment
exp = ClassificationExperiment()- 2行目:クラス分類の検証関係のライブラリをインポート
- 3行目:オブジェクトを作っておきます。
# check the type of exp
type(exp)- 2行目:型を確認
# init setup on exp
exp.setup(data, target = 'species', session_id = 123)- 2行目:検証オブジェクトの設定。使うデータ”data”、予測対象は”species”、session_idで乱数シード固定。
下記のようにセッティング結果が表示されます。
Description Value
0 Session id 123
1 Target species
2 Target type Multiclass
3 Target mapping Iris-setosa: 0, Iris-versicolor: 1, Iris-virgi...
4 Original data shape (150, 5)
5 Transformed data shape (150, 5)
6 Transformed train set shape (105, 5)
7 Transformed test set shape (45, 5)
8 Numeric features 4
9 Preprocess True
10 Imputation type simple
11 Numeric imputation mean
12 Categorical imputation mode
13 Fold Generator StratifiedKFold
14 Fold Number 10
15 CPU Jobs -1
16 Use GPU False
17 Log Experiment False
18 Experiment Name clf-default-name
19 USI a996Compare Models モデル比較
(1)まずはFunctionalです。
明示的には、何も指定しないので、いろいろ間違う可能性が多いかな。。。
best = compare_models()1行ですみます。。。が複数のモデルをためすので、少々時間がかかります。
終わると下記のように、複数のモデルの検証結果が表示されます。
Model Accuracy AUC Recall Prec. \
lr Logistic Regression 0.9718 0.9971 0.9718 0.9780
knn K Neighbors Classifier 0.9718 0.9830 0.9718 0.9780
qda Quadratic Discriminant Analysis 0.9718 0.9974 0.9718 0.9780
lda Linear Discriminant Analysis 0.9718 1.0000 0.9718 0.9780
lightgbm Light Gradient Boosting Machine 0.9536 0.9935 0.9536 0.9634
nb Naive Bayes 0.9445 0.9868 0.9445 0.9525
et Extra Trees Classifier 0.9445 0.9935 0.9445 0.9586
catboost CatBoost Classifier 0.9445 0.9922 0.9445 0.9586
gbc Gradient Boosting Classifier 0.9355 0.9792 0.9355 0.9416
xgboost Extreme Gradient Boosting 0.9355 0.9868 0.9355 0.9440
dt Decision Tree Classifier 0.9264 0.9429 0.9264 0.9502
rf Random Forest Classifier 0.9264 ...列方向で
- 1列目:モデルの短縮名
- 2列目:モデルの名前
- 3列目:予測精度(正解率)
- 4列目:予測精度(AUC)
- 5列目:予測精度(Recall)
- 6列目:予測精度(Precition)
最も精度が高かったのは、ロジスティック回帰ですね。アヤメデータはある程度、比較的いくつかの特徴量と相関が強いので、シンプルなモデルの方が精度がでますね。
(2)そしてこちらが、Object Oriented API
事前に定義した、クラスを明示的に使うので、間違いがすくないですよね。
結果は、上のFunctionalと一緒です。
# compare models using OOP
exp.compare_models()Analyze Model 結果分析
confusion matrix 混同行列
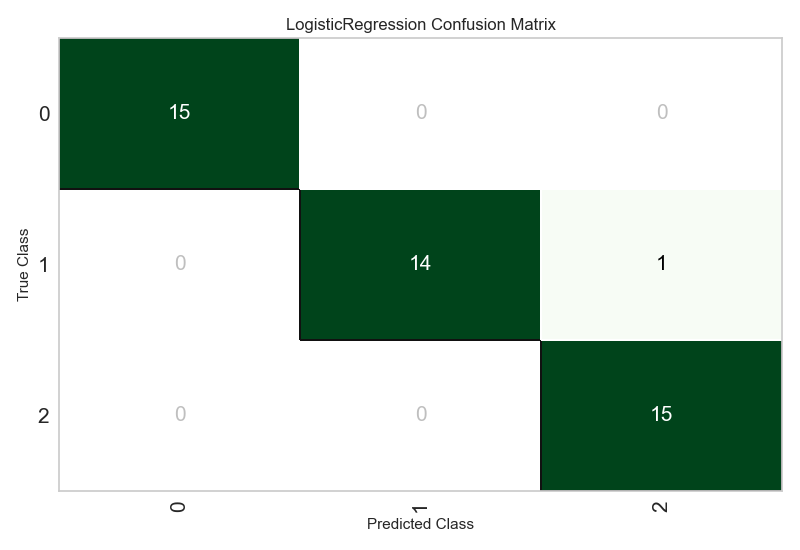
# plot confusion matrix
plot_model(best, plot = 'confusion_matrix')学習済みモデルの検証結果を、plot_modelで様々なグラフで可視化できます。これは便利です!
AUC
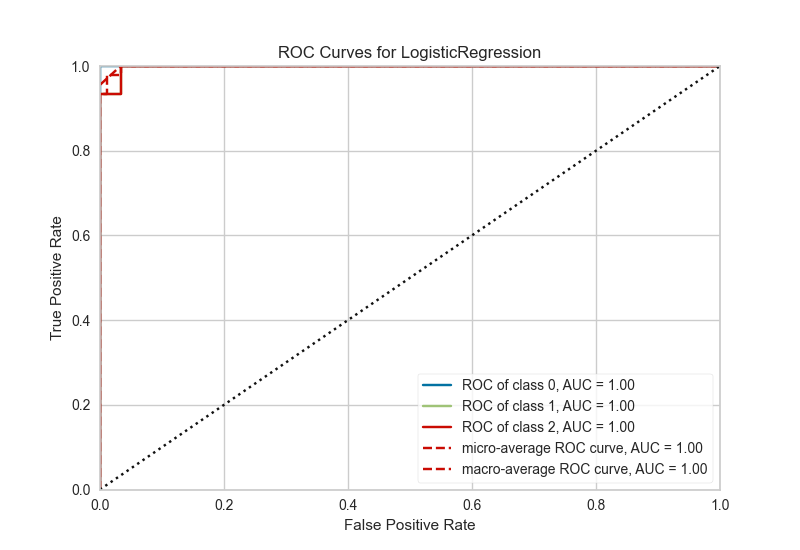
# plot AUC
plot_model(best, plot = 'auc')Uモデルの検証結果を表示します。AUCですね。これも1行で済みます。
特徴量の重要度
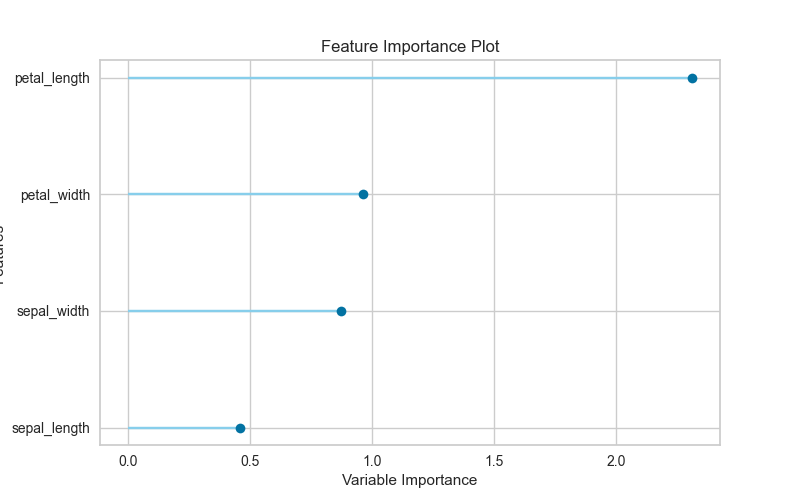
# plot feature importance
plot_model(best, plot = 'feature')特徴量の重要度も、1行で表示してくれます。特徴量を選択する必要があるときは便利ですね。
petal_length(花びらの長さ)とpetal_width(花びらの幅)が、重要度のランク1,2です。
ヘルプでどんなものがプロットできるか確認してみよう
# check docstring to see available plots
help(plot_model)下記のようなものがプロットできます。
estimator: scikit-learn compatible object
Trained model object
plot: str, default = 'auc'
List of available plots (ID - Name):
* 'pipeline' - Schematic drawing of the preprocessing pipeline
* 'auc' - Area Under the Curve
* 'threshold' - Discrimination Threshold
* 'pr' - Precision Recall Curve
* 'confusion_matrix' - Confusion Matrix
* 'error' - Class Prediction Error
* 'class_report' - Classification Report
* 'boundary' - Decision Boundary
* 'rfe' - Recursive Feature Selection
* 'learning' - Learning Curve
* 'manifold' - Manifold Learning
* 'calibration' - Calibration Curve
* 'vc' - Validation Curve
* 'dimension' - Dimension Learning
* 'feature' - Feature Importance
* 'feature_all' - Feature Importance (All)
* 'parameter' - Model Hyperparameter
* 'lift' - Lift Curve
* 'gain' - Gain Chart
* 'tree' - Decision Tree
* 'ks' - KS Statistic Plot- pipline:前処理と機械学習の処理をフロー図(のようなもの)で表示します
- auc:AUC
- thresholod:クラス分けの閾値
- pr:Precision Recall Curve (適合率と再現率のカーブ)
- confusion matrix:混同行列
- error:クラス分類の予測ミス
- class_report:クラス分類のレポート
- boundary:決定境界
- rfe:RFE (Recursive Feature Elimination) で特徴選択
- learning:学習曲線
- mainfold:Mainfold Learningで次元圧縮
- calibration:caribration curve
- vc:validation curve
- dimention:dimention learning(これは、なんでしょうか。。。)
- feature:特徴量の重要度 上の方だけ
- feature_all:特徴量の重要度 全部
- parameter:モデルのハイパーパラメータ
- lift:リフト曲線
- gain:ゲインチャート
- tree:決定木のツリーを表示(かな?)
- ks: kolmogorov-Smirnov plot
たくさんありますが、全部はつかわないですかね。。。
表示をevaluate_modelに変更します。これは、Notebookでのみどうさします。colaboでもOKです。
evaluate_model(best)予測
正解付きの準備されたデータセット
# predict on test set
holdout_pred = predict_model(best)テストデータセットに対して、予測します。
# show predictions df
holdout_pred.head()先頭5データの結果を予測結果を表示します。予測結果はpandas、DataFrameですね。
答えなしのデータで予測
# copy data and drop Class variable
new_data = data.copy()
new_data.drop('species', axis=1, inplace=True)
new_data.head()データを作成しています。
- 3行目:データをコピーして
- 4行目:答えの種類を消して
- 5行目:先頭5データを確認
モデルの保存
# save pipeline
save_model(best, 'my_first_pipeline')モデルの保存も1行ですみます。複数よりが含まれる場合も、パイプラインとして保存します。
# load pipeline
loaded_best_pipeline = load_model('my_first_pipeline')
loaded_best_pipelineこちらは、保存したモデルの読み込みです。
- 2行目:モデルを読み込んで
- 3行目:モデルのパイプラインを表示します。フロー図みたいなものです。
まとめ
今回は、自動機械学習の強力なツールであるpycaretの他クラス分類サンプルコードに解説を加えました。このサンプルコードは、非常に密度の濃い内容ですので、ぜひ動作しながら身に着けてください。
応用へんになる、後半部分は後程解説を加えてみます。

