pythonコードを実装する際、質の良いサンプルコードを参考にすると便利です。ただ、初心者の方にとっては、サンプルコードを読んで理解することに時間がかかってしまうと思います。
そんな方のために、サンプルコードに一段わかりやすい説明を加えます。
今回は、AutoMLのツール、PyCaretのサンプルコードの解説になります。
- AutoMLとPycaret
- サンプルコード解説
- 1.0 Tutorial Objective
- 2.0 Brief overview of techniques covered in this tutorial
- 3.0 Dataset for the Tutorial
- 4.0 Getting the Data(データを取得する)
- 5.0 Setting up Environment in PyCaret(PyCaretの解析設定)
- 6.0 Comparing All Models(いろいろモデルをためして比較)
- 7.0 Create a Model(回帰のアルゴリズムを指定して モデルを作るよ)
- 8.0 Tune a Model モデルのチューニング
- 9.0 Ensemble a Model アンサンブルモデル
- 9.1 Bagging バギング
- 9.2 Boosting ブースティング
- 9.3 Blending ブレンディング
- 9.4 Stacking スタッキング
- まとめ
AutoMLとPycaret
機械学習を扱うプロジェクトではは、満足できる精度がでるまで、ひたすらアルゴリズムを試したり、特徴量に変化を加えたりして行きます。
アルゴリズムをひたすら試すところを自動で行ってくれる、実用的なツールがリリースされており、これらを活用するのが主流となってきました。
AutoMLには
- PyCaret
- TPOT
- DataRobot
- Predict One
- AutoML Table
- Automated ML
などがあります。
この中でも、Pythonのライブラリとして使いやすいのがPyCaretです。
PyCaretのTutorialに、わかりやすいサンプルコードが掲載されていますので、サンプルコードに少し解説を加えて、PyCaretの理解を深めてもらいます。
Pythonに不慣れな方は、こちらも参考にしてください↓↓↓

サンプルコード解説
今回紹介するのは、PyCaretのTutorialに掲載されている。
回帰分析のサンプルコードです。
順番に説明していきます
1.0 Tutorial Objective
チュートリアルの目的が記載されています。チュートリアルの101を理解して人が対象となっております。あまり気にせずに、進んでください。
2.0 Brief overview of techniques covered in this tutorial
本チュートリアルで用いている、機械学習のテクニックの説明が記載されております。
余裕のある方は、読み込んでみてください。初心者の方は飛ばしてOKです。
3.0 Dataset for the Tutorial
データセットの引用元等の説明です、気にしなくてOKです。
4.0 Getting the Data(データを取得する)
ここから実際にPythonコードを動かしていきます!
サンプルコード用のデータを取得します
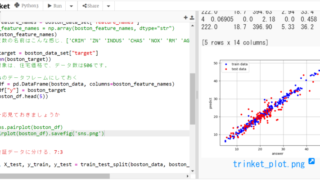
from pycaret.datasets import get_data
dataset = get_data('diamond', profile=True)
print(dataset.head())こちらのサンプルコードでは、ダイアモンドの価格に関するデータです。
データはpandasのDataFrame形式で、下記が先頭5行分となります。DataFrameなのでとても扱いやすいです。
Carat Weight Cut Color Clarity Polish Symmetry Report Price
0 1.10 Ideal H SI1 VG EX GIA 5169
1 0.83 Ideal H VS1 ID ID AGSL 3470
2 0.85 Ideal H SI1 EX EX GIA 3183
3 0.91 Ideal E SI1 VG VG GIA 4370
4 0.83 Ideal G SI1 EX EX GIA 3171説明変数は、「カラット重量」「Cut(切り方)」「Color(色)」「Clarity(クリア感)」「Polich(研磨)」「symmetry(対称性)」「Report(人の評価結果)」の6種類。
目的変数は、「price価格」です。
#check the shape of data
print(dataset.shape)シェイプを確認すると(6000, 8) 。
6000個のダイアモンドのデータがあります。集めるの大変だったでしょう。。。
# データの9割抽出
data = dataset.sample(frac=0.9, random_state=786)
# 残り1割
data_unseen = dataset.drop(data.index)
# indexが歯抜けなのでリセットしておく
data.reset_index(drop=True, inplace=True)
data_unseen.reset_index(drop=True, inplace=True)
print('Data for Modeling: ' + str(data.shape))
print('Unseen Data For Predictions ' + str(data_unseen.shape))
データの9割(ダイアモンド5,400個分)だけ抽出します。乱数を使って、ランダム偏りがないように抽出します。
残りの1割は使わないみたいです。
抽出したデータ(data)は、インデックス(データの番号)が歯抜けになってしまうので、リセットしておきます。(この処理は、もしかしたら必要ないかもしれません。。。)
5.0 Setting up Environment in PyCaret(PyCaretの解析設定)
from pycaret.regression import *
exp_reg102 = setup(data = data, target = 'Price', session_id=123,
normalize = True, transformation = True, transform_target = True,
combine_rare_levels = True, rare_level_threshold = 0.05,
remove_multicollinearity = True, multicollinearity_threshold = 0.95,
bin_numeric_features = ['Carat Weight'],
log_experiment = True, experiment_name = 'diamond1')一番重要なPycaretの設定です。たくさん引数がでてきますね。。。なんと13コ。。。ひとつづつ説明します。
- data
- target
- session_id
- normalize
- transformation
- transform_target
- combine_rare_levels
- rare_level_threshold
- remove_multicollinearity
- multicollinearity_threshold
- bin_numeric_features
- log_experiment
- experiment_name
data :解析に使うデータです。今回はPandasデータフレーム形式
target :dataの中で予測対象にするものの名前。今回は「”Price”」
session_id :乱数シードの管理値です。auto mlでは様々なアルゴリズムで乱数を使っているため設定しておきましょう。
normarize :標準化するか否か
transformation :標準化の時に、分布を正規分布に近づけるか。
transform_target :予測対象にも、transformの対象とするか否か。
combine_rare_levels:カテゴリ変数(数値ではないもの)において、レア(使用頻度が少ない)カテゴリをまとめてしまう。
rare_level_threshold :レアカテゴリの閾値
remove_multicollinearity:多重共線性を取り除くか(2つ以上の似たような変数を、ひとつだけにするか)
multicollinearity_threshold:多重共線性判定の閾値
bin_numeric_features :数値データをカテゴリ変数に変える対象
log_experiment :ログ(途中経過)を残すか
experiment_name :ログの名前
たくさんありますね。。。初心者の方は、すべて理解しなくてOKです。
「data」「target_data」「session_id」くらいを覚えておきましょう。
transformationや、多重共線性の自動排除などを行ってくれるのは、ひとつづつ実装する手間を考えると非常に楽ですね。。。
6.0 Comparing All Models(いろいろモデルをためして比較)
top3 = compare_models(exclude = ['ransac'], n_select = 3)
print(type(top3))
print(top3)compare_modelsで、さまざまな機械学習モデルを試します。
ここを自動でおこなってくれるところがPyCaretのすばらしいところです。。。個別にアルゴリズムを実装して試す必要がなくなりそうです。。。
本サンプルコードのtop3は
- 回帰:LGBMRegressor, transform:box-cox
- 回帰:RandomForestRegressor, transform:box-cox
- 回帰:HuberRegressor, transfrom:box-cox
カテゴリ変数が多く、データ数も多いので、ツリーモデルが有利だと思っておりましたが、線形回帰のHuberRegressorがtop3に入っているのは意外です。。。
理由を考えたいところですが、今回はサンプルコードの説明ですので、深追いはしません。
7.0 Create a Model(回帰のアルゴリズムを指定して モデルを作るよ)
7.0では、6.0で比較して選んだアルゴリズムのモデルを作りこみます。
7.1 Create Model (with 5 Fold CV) 決定木モデルを、クロスバリデーションで学習
“dt”は決定木です。
クロスバリデーションで、”dt”決定木のモデルを作ります。
dt = create_model('dt', fold = 5)精度はRMSEで、2377.6
7.2 Create Model (Metrics rounded to 2 decimals points) ランダムフォレスト
ランダムフォレスト回帰のモデルを作る
rf = create_model('rf', round = 2)精度はRMSEで、1770.5。
さすがランダムフォレスト、精度があがりました。
ランダムフォレストはこちらも参考にしてください。webブラウザー上で動作するサンプルコード付きです↓↓↓
7.3 Create Model (KNN) K近傍法
knn = create_model('knn')
print(knn)K近傍法のモデルを作る
精度はRMSEで、6566.1。
これまでの二つに比べておとります。。。ハイパーパラメータのチューニングが必要だからです。
8.0 Tune a Model モデルのチューニング
create_modelでは、ハイパーパラメータがデフォルト値で作成されるようで。。。
tune_modelでハイパーパラメータをチューニングします。
knnが悪かったみたいなので。。。
tuned_knn = tune_model(knn)
print(tuned_knn)
tuned_knn2 = tune_model(knn, n_iter = 50)
print(tuned_knn2)
plot_model(tuned_knn, plot = 'parameter')
plot_model(tuned_knn2, plot = 'parameter')n_iterという引数をデフォルト値と50で比較しています。
RMSEで、tuned_knnが5913.5、tuned_knn2が5736.4
9.0 Ensemble a Model アンサンブルモデル
ここでは、アンサンブルモデルを作ります。
指定したアルゴリズムをアンサンブルしてくれるようです。
参考までに、基本の決定木
# lets create a simple dt
dt = create_model('dt')
print(dt)精度はRMSE 2138.8
9.1 Bagging バギング
まずは、バギング。(初めからバギングのモデルを選んだほうがいいですかね。。。)
bagged_dt = ensemble_model(dt)
print(bagged_dt)精度はRMSE 1896.5
精度が上がりますね。
9.2 Boosting ブースティング
そして、ブースティング(初めからブースティングのモデルを選んだほうがいいですかね。。。)
boosted_dt = ensemble_model(dt, method = 'Boosting')
bagged_dt2 = ensemble_model(dt, n_estimators=50)精度はRMSE booste_dtが2028.3、bagged_dt2が1800.0
精度は上がります。
9.3 Blending ブレンディング
ブレンディングでは、ligtGBM、決定木、線形回帰 の3手法をブレンドしてみます。
3つのモデルの予測値の平均値を、ブレンディングモデルの予測値として返します。
ブレンディングもひとつづつ実装すると大変ですが、簡単にできてしまいますね。。。
# train individual models to blend
lightgbm = create_model('lightgbm', verbose = False)
dt = create_model('dt', verbose = False)
lr = create_model('lr', verbose = False)
# blend individual models
blender = blend_models(estimator_list = [lightgbm, dt, lr])
# blend top3 models from compare_models
blender_top3 = blend_models(top3)
print(blender_top3.estimators_)精度はRMSEで
LigtGBM、決定木、線形回帰の blenderが 1557.4
top3のアルゴリズムをブレンドした、blender_top3が 1449.1
これが、本サンプルコードの最高スコアです。
9.4 Stacking スタッキング
最後にスタッキングです。
スタッキングは、使いこなすのが難しくあまり一般的に使われていないようです。
ただ、pycaretを使うとうまくいきそうです。
stacker = stack_models(top3)
xgboost = create_model('xgboost')
stacker2 = stack_models(top3, meta_model = xgboost)精度はRMSEで
top3のアルゴリズムをブレンドした、stackerが 1542.4
stacker2が 1658.6
blenderのほうが精度がでてますね。。。
まとめ
自動で、複数の機械学習アルゴリズムを試して比較できる、PyCaretのサンプルコードを解説しました。テーブルデータの分類や回帰ははAutoML(自動機械学習)を活用するのが主流になってきておりますので、皆さんチャレンジしてみてください。
私も、サンプルコードを勉強して、予想以上にコードを書く量が少なく実装できるため、積極的に活用しようと思います。
データサイエンティストの必要なスキルについてまとめた記事もご参考に↓↓↓